



Ensuring data quality checks are really important in data driven projects
- To make sure of data correctness for correct business decisions
- Validate the data beforehand to avoid broken production pipelines
- Validate data from disperse sources(ftp, data lakes or sources other than RDBMS etc.)which doesn't have schema and integrity constraints
- Data quality ensures Machine learning models performance
- Many more…
It would be really time saving to have a tool/framework that could help us in ensuring data quality and we do have multiple tools/frameworks for the same. One such opensource project is Deequ by AWS.
In this post we will try to explore more on the Constrain verification module of Deequ, as we progress lets build a dynamic verification module which takes the deequ rules from a file/or any store/dictionary.
Before that we will go through a quick refresher on AWS Deequ
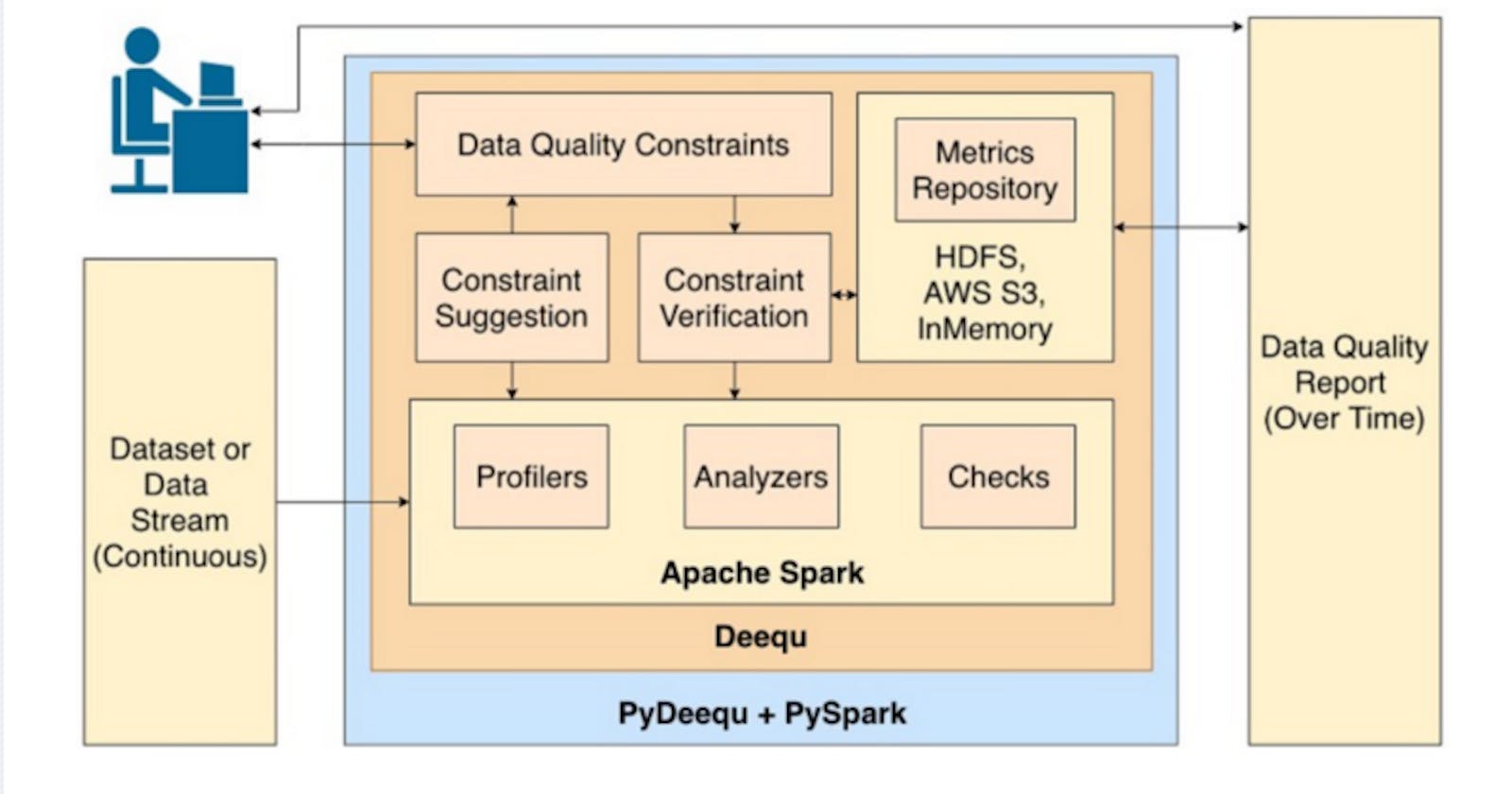
aws documentation — Deequ allows you to calculate data quality metrics on your dataset, define and verify data quality constraints, and be informed about changes in the data distribution. Instead of implementing checks and verification algorithms on your own, you can focus on describing how your data should look. Deequ supports you by suggesting checks for you. Deequ is implemented on top of Apache Spark and is designed to scale with large datasets (think billions of rows) that typically live in a distributed filesystem or a data warehouse.
Long story short, anything that you can fit into Spark dataframe(S3, Snowflake, RDBMS etc.), Deequ helps you to perform Data quality tests, that too at scale.
Deequ have 4 main components
- Metrics computation — Gives statistics insight on data quality such as completeness, correlation, uniqueness etc.
- Constraints suggestion — confused to use which all data qualities check needs to be done? AWS Deequ will give us some suggestions on the top of our data .Please see the constraints suggestion and see what makes more sense before using.
- Constraint verification — We can verify the data by defining quality constraint rules and gives back the status of our checks
- Metrics repository — enables us to store the Deequ results(the metrics we have computed) and then we may use them to compare them with the subsequent Deequ results. During the time I write this post only 2 repository support is there- File and In-memory.
AWS Deequ for generating data quality reports
Constraint verification module helps us to generate data quality reports based on a set of metrics that run on top of our data frame. Please find below example on the usage which I have taken from their git repository.
Note — For this post I have used pydeequ — python wrapper around Deequ(Deequ is originally written in Scala).
from pyspark.sql import SparkSession, Row
import pydeequ
from pydeequ.checks import \*
from pydeequ.verification import \*
spark = (SparkSession
.builder
.config("spark.jars.packages", pydeequ.deequ\_maven\_coord)
.config("spark.jars.excludes", pydeequ.f2j\_maven\_coord)
.getOrCreate())
df = spark.sparkContext.parallelize(\[
Row(a="foo", b=1, c=5),
Row(a="bar", b=2, c=6),
Row(a="baz", b=3, c=None)\]).toDF()
check = Check(spark, CheckLevel.Warning, "Review Check")
checkResult = VerificationSuite(spark) \\
.onData(df) \\
.addCheck(
check.hasSize(lambda x: x >= 3) \\
.hasMin("b", lambda x: x == 0) \\
.isComplete("c") \\
.isUnique("a") \\
.isContainedIn("a", \["foo", "bar", "baz"\]) \\
.isNonNegative("b")) \\
.run()
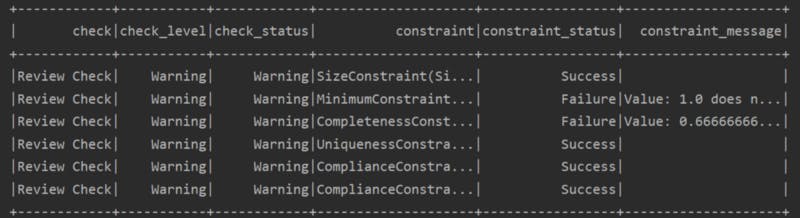
checkResult\_df = VerificationResult.checkResultsAsDataFrame(spark, checkResult)
checkResult\_df.show()
- hasSize — Check the size of our data frame greater than 3 — Success/fail
- hasMin — Check if the minimum value of b column is 0 — Success/fail
- isComplete — Check if all the values of c are not null — Success/fail
- isUnique — Check if all the values of a is unique — Success/fail
- isContainedIn — Check if the value of is in the given list — Success/fail
- isNonNegative — Check if all the values of b are non negative — Success/fail
Details of all the available quality checks — click here
Output
Sample Use case
We will try the same example from the pydeequ git repository, but passing those constraints dynamically. For simplicity, we will configure our deequ rules in a python dictionary, you shall configure it in a file/key value store/anywhere. Please refer here for the complete code
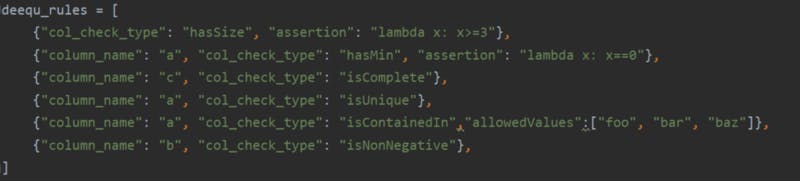
- Configure Deequ rules
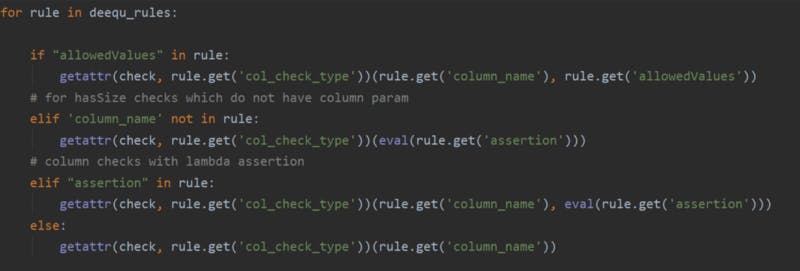
- Initialize Check object state

- Create constraints from string
For this we will leverage getattr in python — reference, which is a reflection enabling function in python
- Call VerificationSuite which is responsible for running our checks and pass our dataframe on which checks needs to be run and the check object itself

- Get check results

Thats it..

output
Summary
In this post we had a quick refresher on AWS Deequ and discussed a sample use case to build a dynamic verification module which takes the deequ rules from a file/or any store/dictionary, which brought some flexibility to our module. You can always take this into another level by
- Describing appropriate actions to take based on the verification module status, like sending notification if you see a quality breach in your data.
- Design and configure a Deequ rule repository, where users can configure new rules
Thanks hope this helps!