





I stumbled upon DuckDB recently when I was doing data analysis with python Pandas. The 3 steps - set up/installation, data exploration, and execution, and it was a very pretty quick implementation.
In this post, we will be discussing DuckDB, and what DuckDB is not and will also see a sample snippet for querying pandas using DuckDB.
DuckDB is similar to SQLite(in fact coined with the term -SQLite for Analytics)- from a quick installation and embedded database perspective, but the difference is SQLite is designed for OLTP workloads. The initial motivation for the DuckDB has been started with a thought to design a solution for analytics for the data that can fit in memory to avoid the propagation of the data to an RDBMS just to do the analytics
DuckDB has been pretty well documented here, following are the key takeaways.
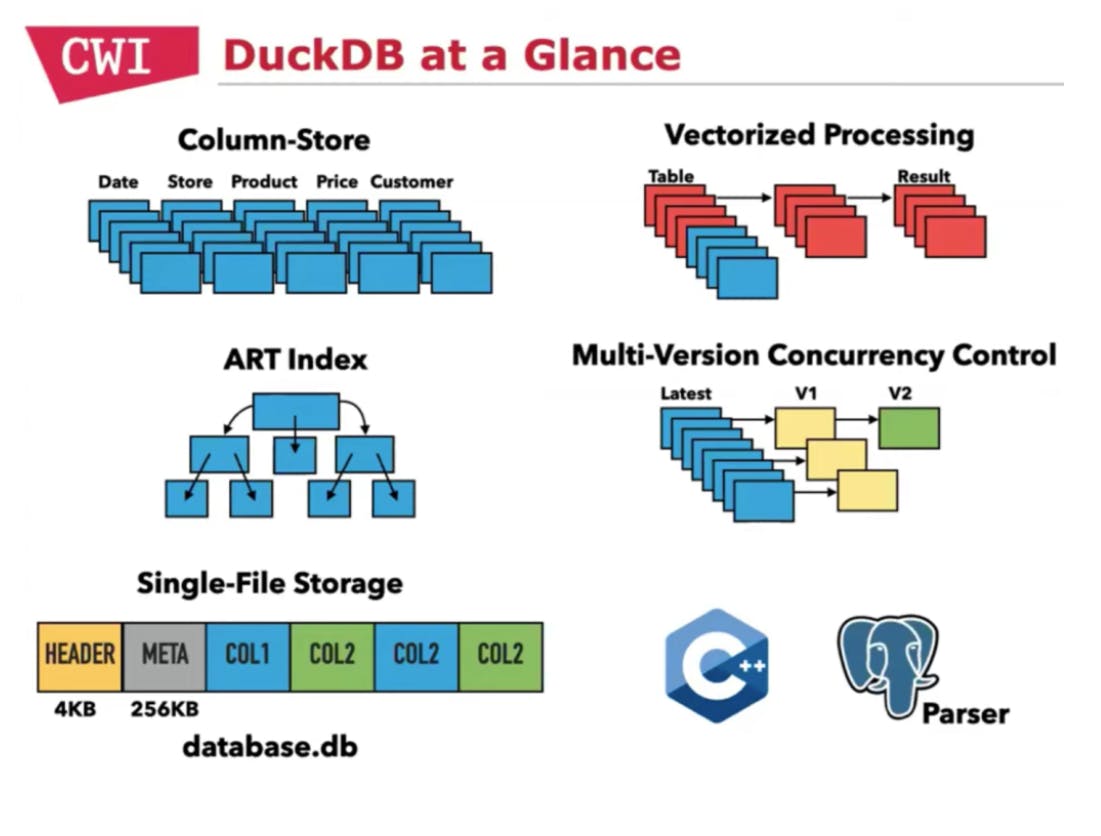
Especially build for OLAP workloads - DuckDB via a columnar vectorized query execution engine, a large batch of values is processed in one operation, unlike a standard query execution engine which processes one row at a time. In other words, each column will be stored as a vector.
Simple Installation - Integrated to package manager!
pip install duckdb
and you are done with the setup!. Just like SQLite.
SQL Support - Like any other SQL-based RDBMS we can write SQL queries for data wrangling/analysis. Writing SQL on top of your pandas dataframe efficiently and without ever leaving the pandas Dataframe binary format - even better. We can also use relational API that can be used to chain together query operations. Click here for Benchmark results
Handles data efficiently within a single machine- for the data that fits in a single machine.
Direct Parquet/CSV querying - Out-of-box support to read and write parquet/CSV files
Multi-Version Concurrency Control - Aimed primarily for bulk Insert/Update/Delete, not the transactional workload perspective concurrency.
import duckdb
# to start an in-memory database
con = duckdb.connect(database=':memory:')
# to use a database file (not shared between processes)
con = duckdb.connect(database='my-db.duckdb', read_only=False)
# to use a database file (shared between processes)
con = duckdb.connect(database='my-db.duckdb', read_only=True)
What DuckDB is not
Not a transactional database
Not a replacement for the use case that fits distributed workloads. But efficiently works with data that can fit in a single instance.
Querying Pandas
We can work with Pandas using DuckDB either using SQL Query or Relational API. When SQL Query offers the advantage of ease of use, relational API helps to lazily evaluate the query operations chained together which will help in the optimization of the execution. The following example has been taken from DuckDB official documentation.
import duckdb
import pandas
# connect to an in-memory database
con = duckdb.connect()
input_df = pandas.DataFrame.from_dict({'i':[1,2,3,4],
'j':["one", "two", "three", "four"]})
# create a DuckDB relation from a dataframe
rel = con.df(input_df)
# chain together relational operators (this is a lazy operation, so the operations are not yet executed)
transformed_rel = rel.filter('i >= 2').project('i, j, i*2 as two_i').order('i desc').limit(2)
# trigger execution by requesting .df() of the relation
relational_df = transformed_rel.df()
print('df using relational API ')
print(relational_df)
## SQL ON PANDAS
sql_df=con.execute('SELECT i, j, i*2 as two_i FROM input_df ORDER BY i desc limit 2').df()
print('df using sql query ')
print(sql_df)
A further extensive example can be found here. As mentioned in the above code snippet the relational operators are lazily evaluated until an execution action is called upon.
Summary
In this post we have gone through DuckDB a simple, fast vectorized embedded database optimized for analytics and have also had a closer look at each of its features, what it is not and how to query pandas using both relational API and SQL.