

Handling schema changes in snowflake


With spark-snowflake connector writes
We have discussed the internals of spark snowflake writes in the previous post, in this post lets observe how the schema changes such as missing column/extra columns, data type changes behaves with spark-snowflake connector writes. In other words how the schema mismatch between the spark dataframe and snowflake table are handled.
Click here - Spark Snowflake Write - Behind the Scenes
- Say we have a requirement of ingesting and appending data from source(files or JDBC source systems) to a landing Snowflake table.
- And there are n number of downstream systems that consumes data from these landing zone tables
- The schema changes need not get propagated from source to this landing snowflake table and the data pipeline should not also fail on these schema changes( or in fact ignore the schema changes).
There might be some schema changes that won’t appear as straightforward and might need thought through data pipelines to handle these schema changes holistically, but the purpose of this post is to identify the straightforward scenarios and corresponding solution, which might not need complicated solutions or overengineered data pipelines to handle such use cases. Remember simplification is the ultimate sophistication :)
There are 5 ways to handle simple schema changes in the sources(depending up on scenarios)
- See if we can create a dataframe with the same schema as snowflake landing table, irrespective of the schema changes and use that data frame to write/append to snowflake table.
- See if we can leverage the spark-Snowflake append mode with snowflake mapping properties to handle some of the schema changes scenario.
- Or by design using a landing Snowflake tables with variant columns and build a standardized layer after that.
- Create landing tables with all columns with varchar and cast it as per business meaning of the columns in the subsequent layers
In this post lets explore more on Option 2.Hope it saves you some testing time as well
Please note that all the schema change impact are discussed on the append mode context(as append mode doesn’t change the schema of the target snowflake table), I have also added an extra note/reference on the overwrite mode in this post.
Lets first create a table with some sample data as mentioned in below snippet. As I want spark connector to create the snowflake table for me, choosing overwrite mode for first time load.
df = spark.createDataFrame(
\[
("Aparna", "Learning",'original')
\],
\["NAME", "ACTIVITY","COMMENTS"\])
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_SC\_TEST")\\
.mode("overwrite")\\
.save()
Table Schema
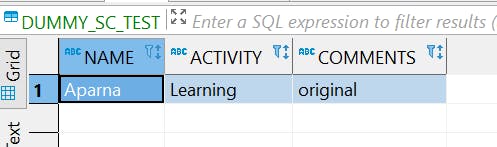
Table Content
Behavior of schema changes
- Column order change
df = spark.createDataFrame(
\[
("Learning", "Aparna",'column order change')
\],
\["ACTIVITY", "NAME","COMMENTS"\])
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_SC\_TEST")\\
.mode("append")\\
.save()

Row 2 — Column order change
By default spark snowflake connector maps the column based on column order, which have resulted in the wrong mapping here. If we need to map the columns based on column names irrespective of their order, we may use the property “column_mapping”:”name” while setting snowflake options.
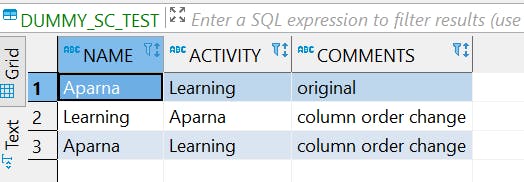
Row 3- Despite of column order change mapped based on the column names
- Column missing
df = spark.createDataFrame(
\[
("Learning", 'column missing')
\],
\["ACTIVITY","COMMENTS"\])
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_SC\_TEST")\\
.mode("append")\\
.save()
If a column is missing without the property column mapping=name(default column order mapping) set, it will throw an exception
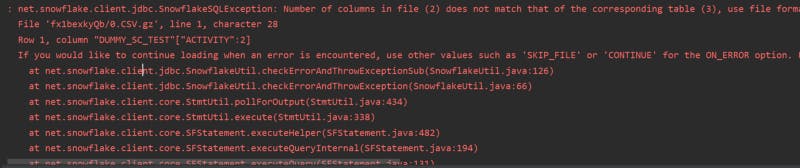
Like before lets set column_mapping as name and see, how it behaves with missing column

Again threw error complaining about column number mismatch. Lets try setting one more snowflake option “column_mismatch_behavior”:”ignore”
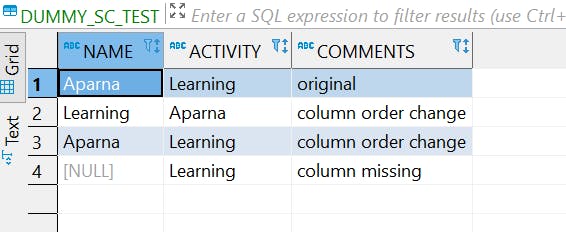
Row 4 — Missing column populated as null
Voila, the missing column has been populated as null with the new property
Please note that the column mismatch behavior is applicable when the column mapping param is set to “name”.By default the column_mismatch_behavior is ‘error’ like we have seen before.
- Extra Column
Since we learned from our previous example that column_mapping name with column_mismatch_behaviour as ignore, will help us with the scenario where number of columns differ between snowflake and spark data frame, lets try those property with a scenario where we have an extra column.
df = spark.createDataFrame(
\[
("Aparna","Learning", 'medium','column addition')
\],
\["NAME","ACTIVITY","PORTAL","COMMENTS"\])
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_SC\_TEST")\\
.mode("append")\\
.save()

Row 5 — extra column ignored
As the column name ‘PORTAL’ is not defined in the target snowflake table, it got ignored and mapped the rest of the columns correctly
- Column data type change behavior
Lets assume the name column have numeric data type
df = spark.createDataFrame(
\[
(123,"Learning",'data type change')
\],
\["NAME","ACTIVITY","COMMENTS"\])
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_SC\_TEST")\\
.mode("append")\\
.save()
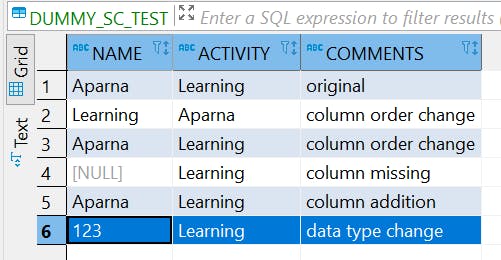
Row 6 — Numeric value 123 mapped to “123” varchar
As in the target table, data type is varchar, the numeric column name got casted to varchar.The reverse is also true, as long as the value can be parsed to a number.
df = spark.createDataFrame(
\[
("Aparna","Learning",'original',"123")
\],
\["NAME","ACTIVITY","COMMENTS","USER\_ID"\])
df.printSchema()
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_DT\_TYPE")\\
.mode("append")\\
.save()
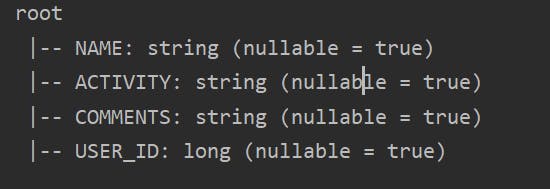
Spark Data types
df = spark.createDataFrame(
\[
("Aparna","Learning",'varchar insert to numeric column',38.00)
\],
\["NAME","ACTIVITY","COMMENTS","USER\_ID"\])
df.printSchema()
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_DT\_TYPE")\\
.mode("append")\\
.save()


Row 3 — 38.00 mapped to 38
Date and Timestamp
df = spark.createDataFrame(
\[
("Aparna","Learning",'original')
\],
\["NAME","ACTIVITY","COMMENTS"\])
#Add timestamp column in the dataframe
df=df.withColumn("TIMESTAMP\_COLUMN",F.current\_timestamp())
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_DT\_TYPE")\\
.mode("overwrite")\\
.save()
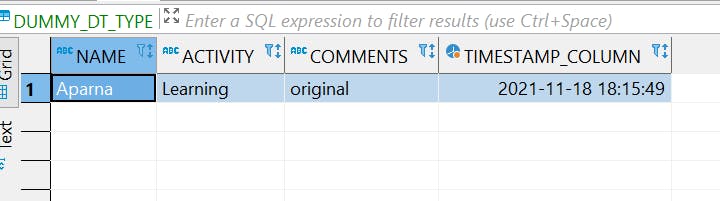
Row 1 — Table with Timestamp column
Lets try to append the table with a string value for timestamp column as mentioned below
df = spark.createDataFrame(
\[
("Aparna","Learning",'Timestamp col as string','2021-11-18 20:15:49')
\],
\["NAME","ACTIVITY","COMMENTS","TIMESTAMP\_COLUMN"\])
df.write\\
.format(SNOWFLAKE\_SOURCE\_NAME)\\
.options(\*\*sfOptions)\\
.option("dbtable", "DUMMY\_DT\_TYPE")\\
.mode("append")\\
.save()

Error when trying to insert timestamp string in a timestamp column
Even though we have handled these schema changes with the simple setting, it is a best practice to notify or log the schema changes somewhere, so that business can decide in future whether to incorporate these changes.
- Overwrite mode
How to: Load Data in Spark with Overwrite mode without Changing Table Structure (snowflake.com)
Summary
In this post we have discussed
- how the schema changes in spark dataframe while trying to append to a Snowflake schema of different schema impacts
- how could we handle those changes with out much impacting our data pipeline in a simple way.
- This learning can be implemented for the use cases where the Snowflake tables needs to be of static standard schema because of the nature of the downstream systems.
Thank you..
References